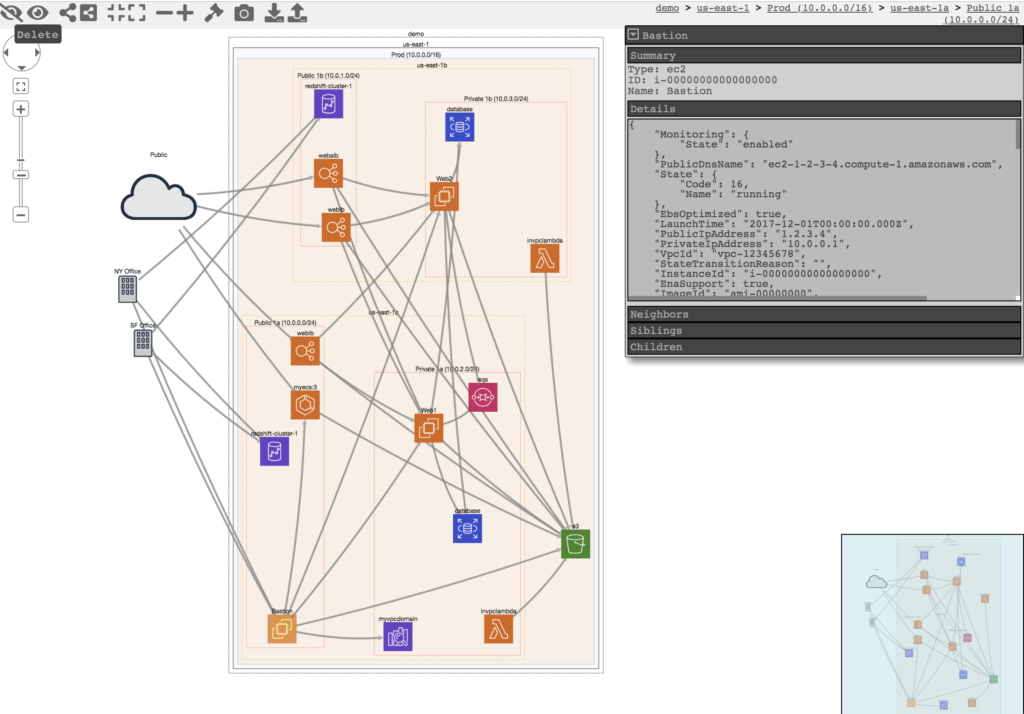
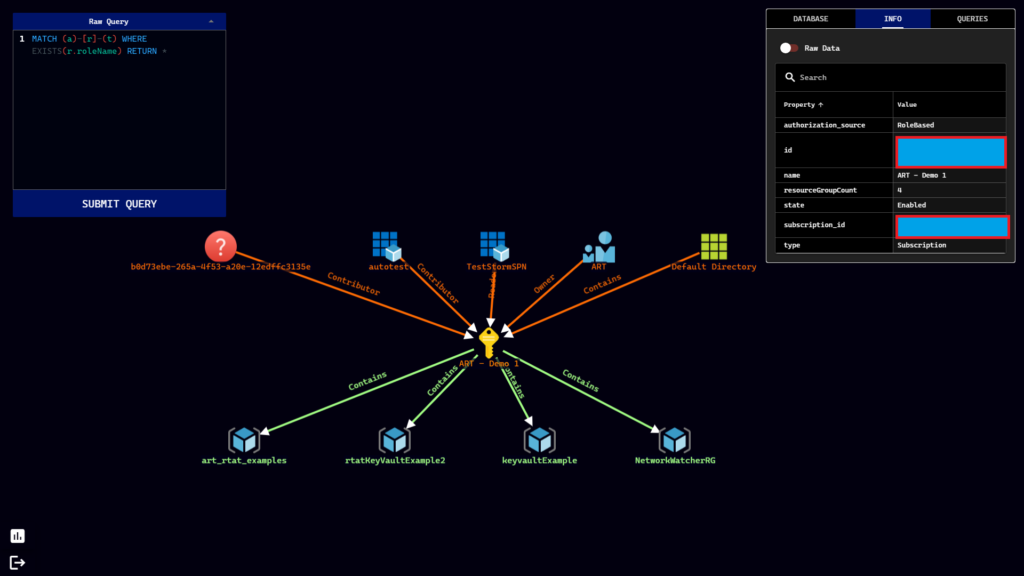
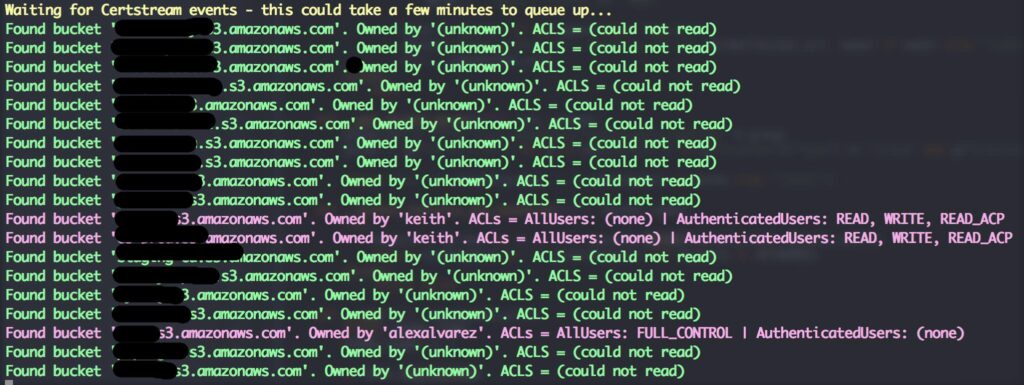
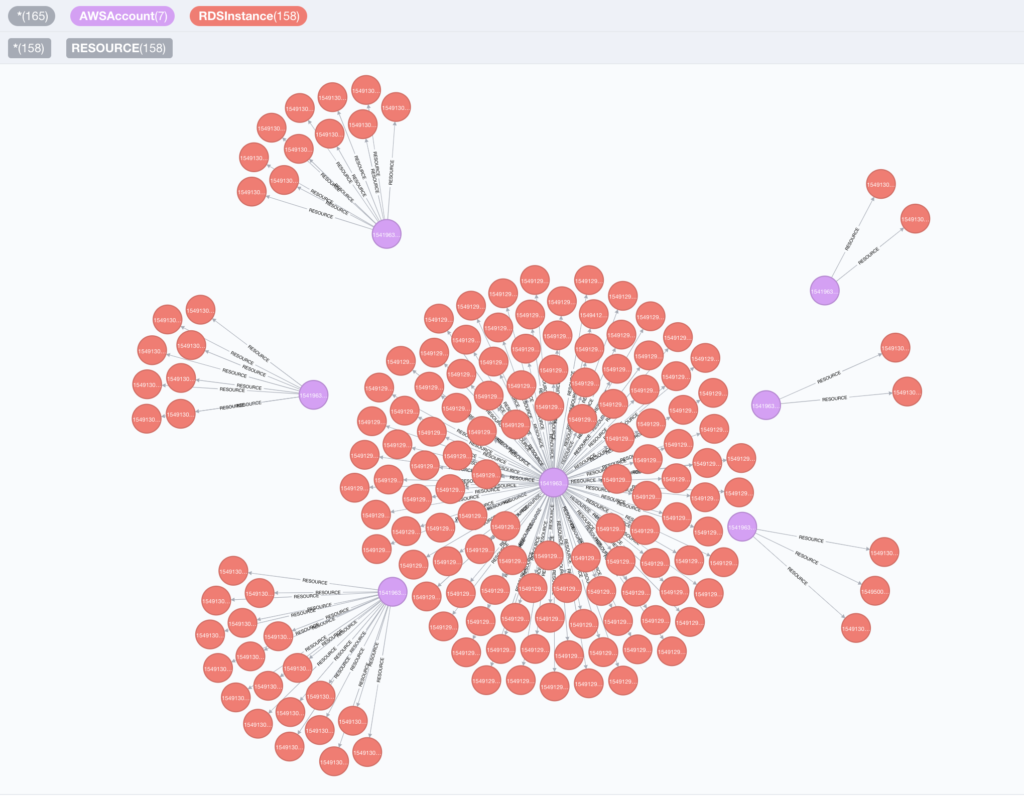
usage: cloud_enum.py [-h] -k KEYWORD [-m MUTATIONS] [-b BRUTE]
Multi-cloud enumeration utility. All hail OSINT!
optional arguments:
-h, --help show this help message and exit
-k KEYWORD, --keyword KEYWORD
Keyword. Can use argument multiple times.
-kf KEYFILE, --keyfile KEYFILE
Input file with a single keyword per line.
-m MUTATIONS, --mutations MUTATIONS
Mutations. Default: enum_tools/fuzz.txt
-b BRUTE, --brute BRUTE
List to brute-force Azure container names. Default: enum_tools/fuzz.txt
-t THREADS, --threads THREADS
Threads for HTTP brute-force. Default = 5
-ns NAMESERVER, --nameserver NAMESERVER
DNS server to use in brute-force.
-l LOGFILE, --logfile LOGFILE
Will APPEND found items to specified file.
-f FORMAT, --format FORMAT
Format for log file (text,json,csv - defaults to text)
--disable-aws Disable Amazon checks.
--disable-azure Disable Azure checks.
--disable-gcp Disable Google checks.
-qs, --quickscan Disable all mutations and second-level scans
$ python cdn-search.py -h
usage: cdn-search.py [-h] [-d DOMAIN] [-p PAGES]
optional arguments:
-h, --help Show this help message and exit
-d DOMAIN, --domain DOMAIN
Search censys for certs using domain
-p PAGES, --pages PAGES
Number of pages to retrieve (100/page)
$ python validate-domains.py -h
usage: validate-domains.py [-h] [-f DOMAINS_FILE] [-s SSL] [-c CDN_DOMAIN]
[-o OUTPUT_FILE]
optional arguments:
-h, --help show this help message and exit
-f DOMAINS_FILE, --domains-file DOMAINS_FILE
Path to list of potential frontable domains.
-s SSL, --ssl SSL Prepend domain from list with http or https.
-c CDN_DOMAIN, --cdn-domain CDN_DOMAIN
CDN FQDN for C2.
-o OUTPUT_FILE, --output-file OUTPUT_FILE
Save results to file.
$ festin -h
usage: __main__.py [-h] [--version] [-f FILE_DOMAINS] [-w] [-c CONCURRENCY] [--no-links] [-T HTTP_TIMEOUT] [-M HTTP_MAX_RECURSION] [-dr DOMAIN_REGEX] [-rr RESULT_FILE] [-rd DISCOVERED_DOMAINS] [-ra RAW_DISCOVERED_DOMAINS]
[--tor] [--debug] [--no-print] [-q] [--index] [--index-server INDEX_SERVER] [-dn] [-ds DNS_RESOLVER]
[domains [domains ...]]
Festin - the powered S3 bucket finder and content discover
positional arguments:
domains
optional arguments:
-h, --help show this help message and exit
--version show version
-f FILE_DOMAINS, --file-domains FILE_DOMAINS
file with domains
-w, --watch watch for new domains in file domains '-f' option
-c CONCURRENCY, --concurrency CONCURRENCY
max concurrency
HTTP Probes:
--no-links extract web site links
-T HTTP_TIMEOUT, --http-timeout HTTP_TIMEOUT
set timeout for http connections
-M HTTP_MAX_RECURSION, --http-max-recursion HTTP_MAX_RECURSION
maximum recursison when follow links
-dr DOMAIN_REGEX, --domain-regex DOMAIN_REGEX
only follow domains that matches this regex
Results:
-rr RESULT_FILE, --result-file RESULT_FILE
results file
-rd DISCOVERED_DOMAINS, --discovered-domains DISCOVERED_DOMAINS
file name for storing new discovered after apply filters
-ra RAW_DISCOVERED_DOMAINS, --raw-discovered-domains RAW_DISCOVERED_DOMAINS
file name for storing any domain without filters
Connectivity:
--tor Use Tor as proxy
Display options:
--debug enable debug mode
--no-print doesn't print results in screen
-q, --quiet Use quiet mode
Redis Search:
--index Download and index documents into Redis
--index-server INDEX_SERVER
Redis Search ServerDefault: redis://localhost:6379
DNS options:
-dn, --no-dnsdiscover
not follow dns cnames
-ds DNS_RESOLVER, --dns-resolver DNS_RESOLVER
comma separated custom domain name servers